Hadoop集群安装
机器
如果只有3台主机,可以按照如下规划来部署安装
| IP | server |
|---|---|
| hadoop1(172.16.185.68) | zookeeper journalnode namenode zkfc resourcemanager datanode |
| hadoop2(172.16.185.69) | zookeeper journalnode namenode zkfc resourcemanager datanode |
| hadoop3(172.16.185.70) | zookeeper journalnode datanode |
创建用户组hadoop、创建用户hadoop
[root@master ~]$ groupadd hadoop
[root@master ~]$ adduser -g hadoop -d /home/hadoop hadoop
[root@master ~]$ useradd -s /bin/bash -d /home/hadoop -m hadoop -g hadoop -G root
[root@master ~]$ passwd hadoo
[root@hadoop1 data]# chown -R hadoop:hadoop /data/
修改主机名
vi /etc/sysconfig/network
绑定hosts
[root@hadoop1 ~]# vi /etc/hosts
172.16.185.68 hadoop1
172.16.185.69 hadoop2
172.16.185.70 hadoop3
免密码登录
切换hadoop用户
[root@hadoop1 ~]#
[root@hadoop1 ~]# su hadoop
[hadoop@hadoop1 test]$
配置免密码登陆
#首先要配置hadoop1到hadoop2、hadoop3的免密码登陆
#在hadoop1上生产一对钥匙 yum -y install openssh-clients
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
/usr/bin/ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
#配置hadoop2到hadoop1、hadoop3的免密码登陆
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
zookeeper安装
hadoop2.0集群搭建
安装配置hadoop集群(在hadoop1上操作)
解压
tar -zxvf /data/software/hadoop-2.5.2.tar.gz -C /data/
配置HDFS
hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/data/java
export HADOOP_HOME=/data/hadoop-2.5.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /data/hadoop-2.5.2/etc/hadoop
修改hadoo-env.sh
export JAVA_HOME=/data/java
修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-2.5.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop2:2181</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!--取消hadoop hdfs的用户权限检查 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop-2.5.2/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Spark on yarn ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state FINISHED!-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
修改slaves
hadoop1
hadoop2
hadoop3
将配置好的hadoop拷贝到其他节点
scp -r /data/hadoop-2.5.2/ hadoop2:/data/
scp -r /data/hadoop-2.5.2/ hadoop3:/data/
启动集群
注意:严格按照下面的步骤
启动zookeeper集群
分别在hadoop1、hadoop2、hadoop3上启动zk
启动journalnode
分别在在hadoop1、hadoop2、hadoop3上执行
/data/hadoop-2.5.2/sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,多了JournalNode进程
格式化HDFS
#在hadoop1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/data/hadoop-2.5.2/tmp/,然后将/data/hadoop-2.5.2/tmp/拷贝到hadoop2的/data/hadoop-2.5.2/下。
scp -r /data/hadoop-2.5.2/tmp/ hadoop2:/data/hadoop-2.5.2/
##也可以这样,建议hdfs namenode -bootstrapStandby
格式化ZKFC(在hadoop1上执行即可)
hdfs zkfc -formatZK
启动HDFS(在hadoop1上执行)
/data/hadoop-2.5.2/sbin/start-dfs.sh
启动YARN
注意:是在hadoop3上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动
/data/hadoop-2.5.2/sbin/start-yarn.sh
到此,hadoop-2.5.2配置完毕,可以统计浏览器访问:
http://hadoop1:50070 Overview ‘hadoop1:9000’ (standby)
http://hadoop2:50070 Overview ‘hadoop2:9000’ (active)
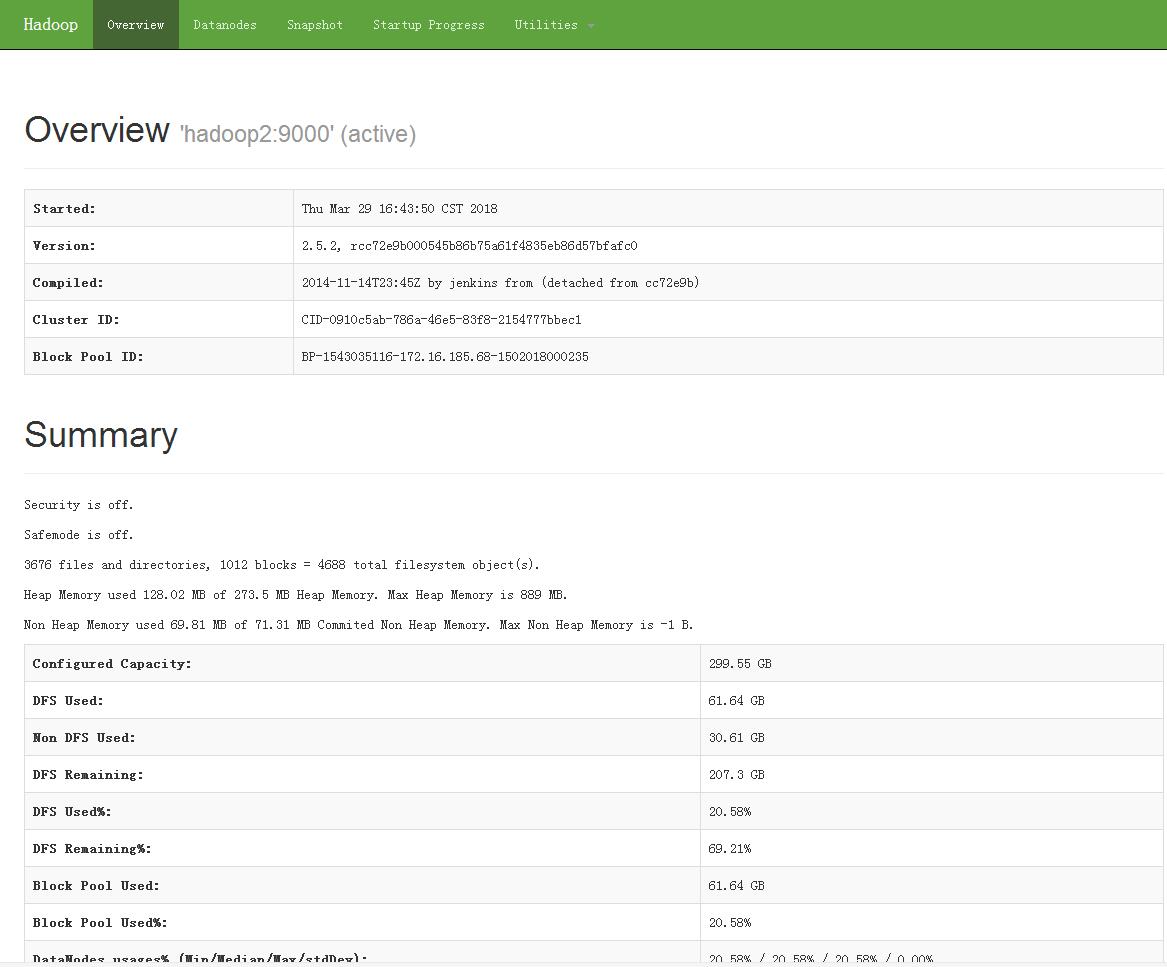
cluster调度页面
http://hadoop1:8088/cluster
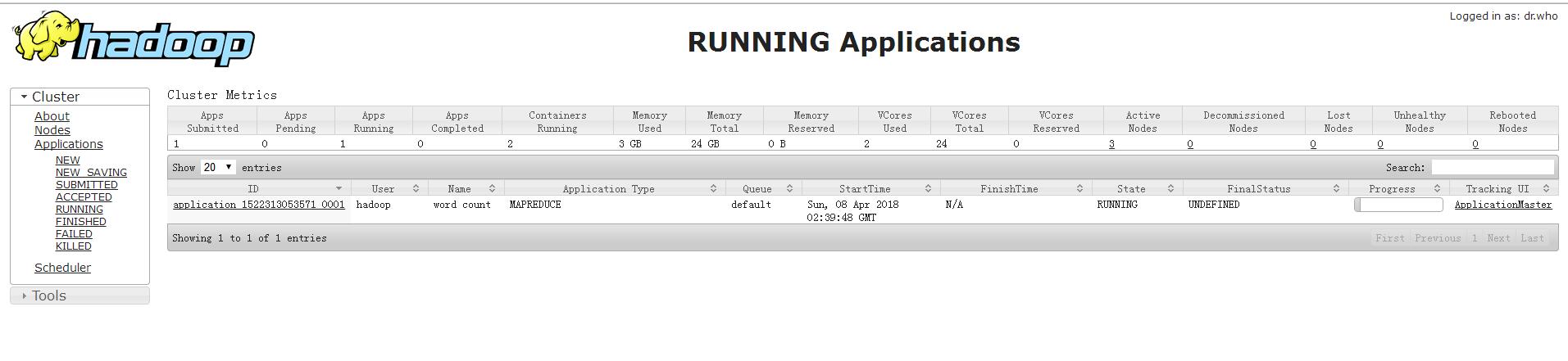
启动集群
root切换用户
su hadoop
hadoop1上
/data/hadoop-2.5.2/sbin/start-dfs.sh
/data/hadoop-2.5.2/sbin/start-yarn.sh
停止集群
hadoop1上
/data/hadoop-2.5.2/sbin/stop-dfs.sh
/data/hadoop-2.5.2/sbin/stop-yarn.sh
验证HDFS HA
首先向hdfs上传一个文件
[hadoop@hadoop1 test]$ hadoop fs -put /etc/profile /profile
[hadoop@hadoop1 test]$ hadoop fs -ls /
Found 4 items
-rw-r--r-- 3 hadoop supergroup 2309 2017-08-06 19:21 /profile
drwx-wx-wx - hadoop supergroup 0 2017-09-03 18:58 /tmp
drwxr-xr-x - hadoop supergroup 0 2017-09-03 19:18 /user
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:http://hadoop2:50070
NameNode 'hadoop2:9000' (active)
这个时候hadoop2上的NameNode变成了active
再执行命令:
[hadoop@hadoop1 test]$ hadoop fs -ls /
Found 4 items
-rw-r--r-- 3 hadoop supergroup 2309 2017-08-06 19:21 /profile
drwx-wx-wx - hadoop supergroup 0 2017-09-03 18:58 /tmp
drwxr-xr-x - hadoop supergroup 0 2017-09-03 19:18 /user
刚才上传的文件依然存在!!!手动启动那个挂掉的NameNode
hadoop-daemon.sh start namenode
通过浏览器访问:http://hadoop1:50070
NameNode 'hadoop1:9000' (standby)
验证YARN: 运行一下hadoop提供的demo中的WordCount程序:
[hadoop@hadoop1 mapreduce]$ hadoop jar /data/hadoop-2.5.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar wordcount /profile /out
18/04/08 10:39:47 INFO input.FileInputFormat: Total input paths to process : 1
18/04/08 10:39:47 INFO mapreduce.JobSubmitter: number of splits:1
18/04/08 10:39:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1522313053571_0001
18/04/08 10:39:48 INFO impl.YarnClientImpl: Submitted application application_1522313053571_0001
18/04/08 10:39:48 INFO mapreduce.Job: The url to track the job: http://hadoop1:8088/proxy/application_1522313053571_0001/
18/04/08 10:39:48 INFO mapreduce.Job: Running job: job_1522313053571_0001
18/04/08 10:39:55 INFO mapreduce.Job: Job job_1522313053571_0001 running in uber mode : false
18/04/08 10:39:55 INFO mapreduce.Job: map 0% reduce 0%
18/04/08 10:40:02 INFO mapreduce.Job: map 100% reduce 0%
18/04/08 10:40:08 INFO mapreduce.Job: map 100% reduce 100%
18/04/08 10:40:08 INFO mapreduce.Job: Job job_1522313053571_0001 completed successfully
18/04/08 10:40:08 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=2697
FILE: Number of bytes written=204315
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2392
HDFS: Number of bytes written=1916
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4160
Total time spent by all reduces in occupied slots (ms)=3305
Total time spent by all map tasks (ms)=4160
Total time spent by all reduce tasks (ms)=3305
Total vcore-seconds taken by all map tasks=4160
Total vcore-seconds taken by all reduce tasks=3305
Total megabyte-seconds taken by all map tasks=4259840
Total megabyte-seconds taken by all reduce tasks=3384320
Map-Reduce Framework
Map input records=92
Map output records=312
Map output bytes=3297
Map output materialized bytes=2697
Input split bytes=83
Combine input records=312
Combine output records=194
Reduce input groups=194
Reduce shuffle bytes=2697
Reduce input records=194
Reduce output records=194
Spilled Records=388
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=147
CPU time spent (ms)=1920
Physical memory (bytes) snapshot=424648704
Virtual memory (bytes) snapshot=4261941248
Total committed heap usage (bytes)=328204288
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2309
File Output Format Counters
Bytes Written=1916
查看结果
[hadoop@hadoop1 mapreduce]$ hadoop fs -cat /out/part-r-00000
18/04/08 10:41:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
!= 1
" 2
"$-" 1
"$2" 1
"$EUID" 2
"$HISTCONTROL" 1
"$cmd"; 1
"$i" 3
"${-#*i}" 1
"+%y-%m-%d 1
"0" 1
":${PATH}:" 1
"`id 2
"after" 1
"ignorespace" 1
"{print 2
.....
配置环境变量
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/data/hadoop-2.5.2
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
OK,大功告成!!!